tdjs.tech blog
What on earth is pseudolocalization, anyway?
Published 2019-06-12
A brief primer on what pseudolocalization is and how you can use it in your own project.
When you're in the early stages of internationalising your website or application, you likely don't want to go through the effort of translating all of your English strings to other languages just yet. It's time consuming, and it's complicated. How will you know if translated strings are in the correct places if you don't speak the language?
Using translated strings can cause unforeseen problems, such as:
- Your typeface may not support glyphs and diacritic marks used in other languages
- Different sized glyphs may cause issues with your line heights and vertical rhythm
- Translated strings may be much longer than their English equivalents, meaning that they overflow their bounds in your interface
These are all problems that you want to catch early. In comes pseudolocalization - the practice of transforming English strings into something that resembles English, but isn't quite the same, so that you can catch these issues during the development cycle. Different glyphs are used to create a sort of pseudo-English, which is still readable to developers but different enough to see how your application will handle the nuances of translation.
For example, the string
This is an English string
becomes
Tλïƨ ïƨ áñ Éñϱℓïƨλ ƨƭřïñϱ
You may also wish to enclose strings in opening and closing brackets, so it is easy to spot if they are being clipped or overflowing their bounds
[!!! Tλïƨ ïƨ áñ Éñϱℓïƨλ ƨƭřïñϱ !!!]
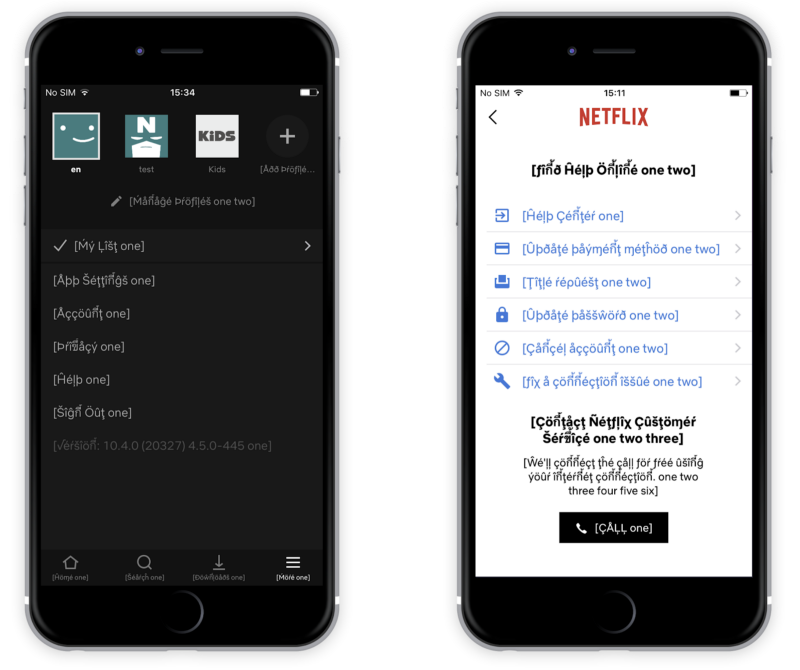
Below is an example from the Netflix iOS app:
A common way to include translated strings in your project is to have a JSON file containing all of your translations, for example:
{
"en": {
"welcomeMessage": "Welcome to my new application!",
"errorMessage": "Oops, it looks like an error occurred",
"loremIpsum": "Lorem ipsum dolor sit amet"
},
"pseudo": {
"welcomeMessage": "Wèℓçô₥è ƭô ₥¥ ñèω áƥƥℓïçáƭïôñ!",
"errorMessage": "Óôƥƨ, ïƭ ℓôôƙƨ ℓïƙè áñ èřřôř ôççúřřèδ",
"loremIpsum": "£ôřè₥ ïƥƨú₥ δôℓôř ƨïƭ á₥èƭ"
},
"fr": { ... },
"de": { ... },
...
}
Then, when a user of your application sets their localisation, you can grab the strings in their chosen language to use in your interface. When testing, you can simply grab the "pseudo" strings to make sure you've covered all of your interface.
I wrote a handy npm module to aid in the creation of pseudolocalized strings, as it can be quite tedious to go through and translate them by hand. It can either be used progmatically or run on an existing JSON file to output a pseudolocalized file. Let me know if it helped you in any way!
To conclude, pseudolocalization is a great way to stress-test your application for any bugs that may arise due to internationalisation at an early stage, before you go through the effort of doing translations. Anyone developing an international application can definitely benefit from adding this step into their development cycle.
Want to get in touch? You can email me at hello@tdjs.tech or message me via Twitter at @tdjsnelling.
You can also check out more work over at GitHub.